/* Too many mappings? */ if (mm->map_count > sysctl_max_map_count) return -ENOMEM; ......... if (flags & MAP_NORESERVE) { /* We honor MAP_NORESERVE if allowed to overcommit */ if (sysctl_overcommit_memory != OVERCOMMIT_NEVER) vm_flags |= VM_NORESERVE;
/* If vm_flags changed after call_mmap(), we should try merge vma again * as we may succeed this time. */ if (unlikely(vm_flags != vma->vm_flags && prev)) { merge = vma_merge(mm, prev, vma->vm_start, vma->vm_end, vma->vm_flags, NULL, vma->vm_file, vma->vm_pgoff, NULL, NULL_VM_UFFD_CTX); if (merge) { /* ->mmap() can change vma->vm_file and fput the original file. So * fput the vma->vm_file here or we would add an extra fput for file * and cause general protection fault ultimately. */ fput(vma->vm_file); vm_area_free(vma); vma = merge; /* Update vm_flags to pick up the change. */ vm_flags = vma->vm_flags; goto unmap_writable; } }
/* * New (or expanded) vma always get soft dirty status. * Otherwise user-space soft-dirty page tracker won't * be able to distinguish situation when vma area unmapped, * then new mapped in-place (which must be aimed as * a completely new data area). */ vma->vm_flags |= VM_SOFTDIRTY; vma_set_page_prot(vma);
structpage { union { struct {/* Page cache and anonymous pages */ /** * @lru: Pageout list, eg. active_list protected by * lruvec->lru_lock. Sometimes used as a generic list * by the page owner. */ structlist_headlru; /* See page-flags.h for PAGE_MAPPING_FLAGS */ structaddress_space *mapping; pgoff_t index;/* Our offset within mapping. */ /** * @private: Mapping-private opaque data. * Usually used for buffer_heads if PagePrivate. * Used for swp_entry_t if PageSwapCache. * Indicates order in the buddy system if PageBuddy. */ unsignedlongprivate; }; ............. };
union {/* This union is 4 bytes in size. */ /* * If the page can be mapped to userspace, encodes the number * of times this page is referenced by a page table. */ atomic_t _mapcount;
/* * The anon_vma heads a list of private "related" vmas, to scan if * an anonymous page pointing to this anon_vma needs to be unmapped: * the vmas on the list will be related by forking, or by splitting. * * Since vmas come and go as they are split and merged (particularly * in mprotect), the mapping field of an anonymous page cannot point * directly to a vma: instead it points to an anon_vma, on whose list * the related vmas can be easily linked or unlinked. * * After unlinking the last vma on the list, we must garbage collect * the anon_vma object itself: we're guaranteed no page can be * pointing to this anon_vma once its vma list is empty. */ structanon_vma { structanon_vma *root;/* Root of this anon_vma tree */ structrw_semaphorerwsem;/* W: modification, R: walking the list */ atomic_t refcount; unsigned degree; structanon_vma *parent;/* Parent of this anon_vma */ structrb_root_cachedrb_root; };
/* * The copy-on-write semantics of fork mean that an anon_vma * can become associated with multiple processes. Furthermore, * each child process will have its own anon_vma, where new * pages for that process are instantiated. * * This structure allows us to find the anon_vmas associated * with a VMA, or the VMAs associated with an anon_vma. * The "same_vma" list contains the anon_vma_chains linking * all the anon_vmas associated with this VMA. * The "rb" field indexes on an interval tree the anon_vma_chains * which link all the VMAs associated with this anon_vma. */ structanon_vma_chain { structvm_area_struct *vma; structanon_vma *anon_vma; structlist_headsame_vma;/* locked by mmap_lock & page_table_lock */ structrb_noderb;/* locked by anon_vma->rwsem */ unsignedlong rb_subtree_last; #ifdef CONFIG_DEBUG_VM_RB unsignedlong cached_vma_start, cached_vma_last; #endif };
if (!n) n++; while (align<n && align<ALIGN) align += align;
LOCK(lock);
cur += -cur & align-1;
if (n > end-cur) { size_t req = n - (end-cur) + PAGE_SIZE-1 & -PAGE_SIZE;
if (!cur) { brk = __syscall(SYS_brk, 0); brk += -brk & PAGE_SIZE-1; cur = end = brk; }
if (brk == end && req < SIZE_MAX-brk && !traverses_stack_p(brk, brk+req) && __syscall(SYS_brk, brk+req)==brk+req) { brk = end += req; } else { int new_area = 0; req = n + PAGE_SIZE-1 & -PAGE_SIZE; /* Only make a new area rather than individual mmap * if wasted space would be over 1/8 of the map. */ if (req-n > req/8) { /* Geometric area size growth up to 64 pages, * bounding waste by 1/8 of the area. */ size_tmin = PAGE_SIZE<<(mmap_step/2); if (min-n > end-cur) { if (req < min) { req = min; if (mmap_step < 12) mmap_step++; } new_area = 1; } } void *mem = __mmap(0, req, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); if (mem == MAP_FAILED || !new_area) { UNLOCK(lock); return mem==MAP_FAILED ? 0 : mem; } cur = (uintptr_t)mem; end = cur + req; } }
p = (void *)cur; cur += n; UNLOCK(lock); return p; } weak_alias(__simple_malloc, __libc_malloc_impl);
The maximum size of the process’s data segment (initialized data, uninitialized data, and heap). This limit affects calls to brk(2) and sbrk(2), which fail with the error ENOMEM upon encountering the soft limit of this resource.
#ifdef CONFIG_COMPAT_BRK /* * CONFIG_COMPAT_BRK can still be overridden by setting * randomize_va_space to 2, which will still cause mm->start_brk * to be arbitrarily shifted */ if (current->brk_randomized) min_brk = mm->start_brk; else min_brk = mm->end_data; #else min_brk = mm->start_brk; #endif if (brk < min_brk) goto out;
/* * Check against rlimit here. If this check is done later after the test * of oldbrk with newbrk then it can escape the test and let the data * segment grow beyond its set limit the in case where the limit is * not page aligned -Ram Gupta */ if (check_data_rlimit(rlimit(RLIMIT_DATA), brk, mm->start_brk, mm->end_data, mm->start_data)) goto out;
/* * Always allow shrinking brk. * __do_munmap() may downgrade mmap_lock to read. */ if (brk <= mm->brk) { int ret;
/* * mm->brk must to be protected by write mmap_lock so update it * before downgrading mmap_lock. When __do_munmap() fails, * mm->brk will be restored from origbrk. */ mm->brk = brk; ret = __do_munmap(mm, newbrk, oldbrk-newbrk, &uf, true); if (ret < 0) { mm->brk = origbrk; goto out; } elseif (ret == 1) { downgraded = true; } goto success; }
/* Check against existing mmap mappings. */ next = find_vma(mm, oldbrk); if (next && newbrk + PAGE_SIZE > vm_start_gap(next)) goto out;
/* Ok, looks good - let it rip. */ if (do_brk_flags(oldbrk, newbrk-oldbrk, 0, &uf) < 0) goto out; mm->brk = brk;
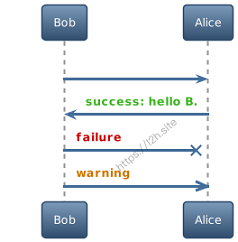
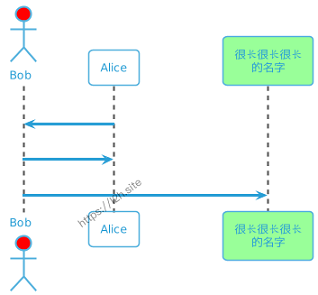
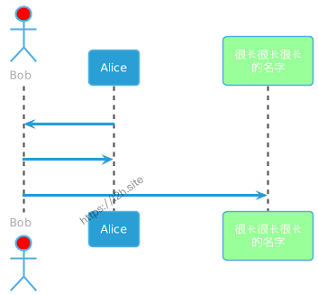
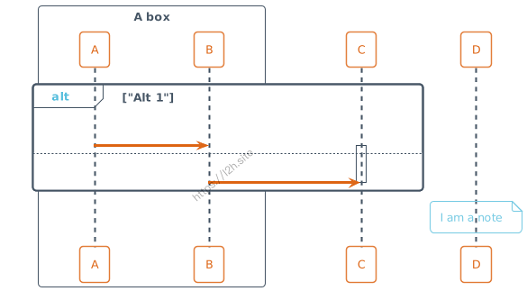
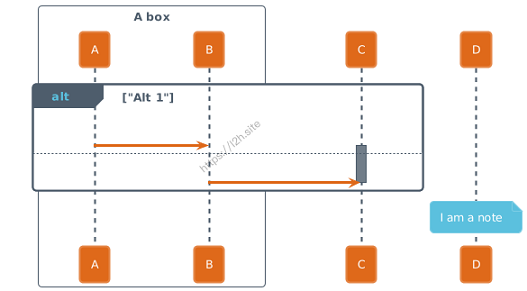
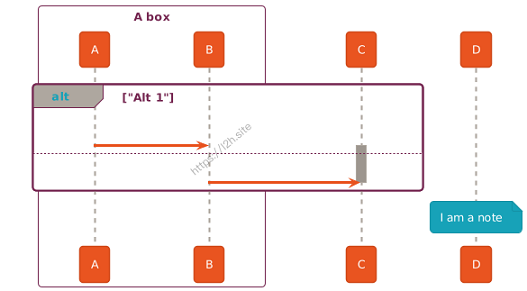
@startuml !theme spacelab Bob -> Alice : hello Bob <- Alice : $success("success: hello B.") Bob -x Alice : $failure("failure") Bob ->> Alice : $warning("warning") @enduml
效果如下:
除了内置主题,也支持本地主题:
1
!theme 主题名 from /本地/摆放/主题的路径
互联网主题也支持,例如:
1
!theme 主题名 from https://raw.githubusercontent.com/plantuml/plantuml/master/themes
choice prompt "Choose SLAB allocator" default SLUB help This option allows to select a slab allocator.
config SLAB bool"SLAB" select HAVE_HARDENED_USERCOPY_ALLOCATOR help The regular slab allocator that is established and known to work well in all environments. It organizes cache hot objects in per cpu and per node queues.
config SLUB bool"SLUB (Unqueued Allocator)" select HAVE_HARDENED_USERCOPY_ALLOCATOR help SLUB is a slab allocator that minimizes cache line usage instead of managing queues of cached objects (SLAB approach). Per cpu caching is realized using slabs of objects instead of queues of objects. SLUB can use memory efficiently and has enhanced diagnostics. SLUB is the default choice for a slab allocator.
config SLOB depends on EXPERT bool"SLOB (Simple Allocator)" help SLOB replaces the stock allocator with a drastically simpler allocator. SLOB is generally more space efficient but does not perform as well on large systems.
typedefstructpglist_data { /* * node_zones contains just the zones for THIS node. Not all of the * zones may be populated, but it is the full list. It is referenced by * this node's node_zonelists as well as other node's node_zonelists. */ structzonenode_zones[MAX_NR_ZONES]; /* * node_zonelists contains references to all zones in all nodes. * Generally the first zones will be references to this node's * node_zones. */ structzonelistnode_zonelists[MAX_ZONELISTS]; ... wait_queue_head_t kswapd_wait; ... structtask_struct *kswapd;/* Protected by mem_hotplug_begin/end() */ int kswapd_order; enum zone_type kswapd_highest_zoneidx; int kswapd_failures;/* Number of 'reclaimed == 0' runs */ unsignedlongtotalreserve_pages; ... } pg_data_t;
staticinlineboolprepare_alloc_pages(gfp_t gfp_mask, unsignedint order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_gfp, unsignedint *alloc_flags) { ac->highest_zoneidx = gfp_zone(gfp_mask); ac->zonelist = node_zonelist(preferred_nid, gfp_mask); ac->nodemask = nodemask; ac->migratetype = gfp_migratetype(gfp_mask); ........ /* * The preferred zone is used for statistics but crucially it is * also used as the starting point for the zonelist iterator. It * may get reset for allocations that ignore memory policies. */ ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask);
retry: /* * Scan zonelist, looking for a zone with enough free. * See also __cpuset_node_allowed() comment in kernel/cpuset.c. */ no_fallback = alloc_flags & ALLOC_NOFRAGMENT; z = ac->preferred_zoneref; for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx, ac->nodemask) { structpage *page; unsignedlong mark;
if (cpusets_enabled() && (alloc_flags & ALLOC_CPUSET) && !__cpuset_zone_allowed(zone, gfp_mask)) continue; if (ac->spread_dirty_pages) { if (last_pgdat_dirty_limit == zone->zone_pgdat) continue;
if (!node_dirty_ok(zone->zone_pgdat)) { last_pgdat_dirty_limit = zone->zone_pgdat; continue; } }
if (no_fallback && nr_online_nodes > 1 && zone != ac->preferred_zoneref->zone) { int local_nid;
/* * If moving to a remote node, retry but allow * fragmenting fallbacks. Locality is more important * than fragmentation avoidance. */ local_nid = zone_to_nid(ac->preferred_zoneref->zone); if (zone_to_nid(zone) != local_nid) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; } }
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK); if (!zone_watermark_fast(zone, order, mark, ac->highest_zoneidx, alloc_flags, gfp_mask)) { int ret;
... /* Checked here to keep the fast path fast */ BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK); if (alloc_flags & ALLOC_NO_WATERMARKS) goto try_this_zone;
if (!node_reclaim_enabled() || !zone_allows_reclaim(ac->preferred_zoneref->zone, zone)) continue;
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order); switch (ret) { case NODE_RECLAIM_NOSCAN: /* did not scan */ continue; case NODE_RECLAIM_FULL: /* scanned but unreclaimable */ continue; default: /* did we reclaim enough */ if (zone_watermark_ok(zone, order, mark, ac->highest_zoneidx, alloc_flags)) goto try_this_zone;
if (!pfn_valid_within(buddy_pfn)) goto done_merging; if (!page_is_buddy(page, buddy, order)) goto done_merging; /* * Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page, * merge with it and move up one order. */ if (page_is_guard(buddy)) clear_page_guard(zone, buddy, order, migratetype); else del_page_from_free_list(buddy, zone, order); combined_pfn = buddy_pfn & pfn; page = page + (combined_pfn - pfn); pfn = combined_pfn; order++; } if (order < MAX_ORDER - 1) { /* If we are here, it means order is >= pageblock_order. * We want to prevent merge between freepages on isolate * pageblock and normal pageblock. Without this, pageblock * isolation could cause incorrect freepage or CMA accounting. * * We don't want to hit this code for the more frequent * low-order merging. */ if (unlikely(has_isolate_pageblock(zone))) { int buddy_mt;
/* special case for empty array */ if (type->regions[0].size == 0) { WARN_ON(type->cnt != 1 || type->total_size); type->regions[0].base = base; type->regions[0].size = size; type->regions[0].flags = flags; memblock_set_region_node(&type->regions[0], nid); type->total_size = size; return0; } repeat: /* * The following is executed twice. Once with %false @insert and * then with %true. The first counts the number of regions needed * to accommodate the new area. The second actually inserts them. */ base = obase; nr_new = 0;
if (rbase >= end) break; if (rend <= base) continue; /* * @rgn overlaps. If it separates the lower part of new * area, insert that portion. */ if (rbase > base) { #ifdef CONFIG_NUMA WARN_ON(nid != memblock_get_region_node(rgn)); #endif WARN_ON(flags != rgn->flags); nr_new++; if (insert) memblock_insert_region(type, idx++, base, rbase - base, nid, flags); } /* area below @rend is dealt with, forget about it */ base = min(rend, end); }
/* insert the remaining portion */ if (base < end) { nr_new++; if (insert) memblock_insert_region(type, idx, base, end - base, nid, flags); }
if (!nr_new) return0;
/* * If this was the first round, resize array and repeat for actual * insertions; otherwise, merge and return. */ if (!insert) { while (type->cnt + nr_new > type->max) if (memblock_double_array(type, obase, size) < 0) return -ENOMEM; insert = true; goto repeat; } else { memblock_merge_regions(type); return0; } }
#ifdef CONFIG_SPARSEMEM_EXTREME structmem_section **mem_section; #else structmem_sectionmem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT] ____cacheline_internodealigned_in_smp; #endif structmem_section { /* * This is, logically, a pointer to an array of struct * pages. However, it is stored with some other magic. * (see sparse.c::sparse_init_one_section()) * * Additionally during early boot we encode node id of * the location of the section here to guide allocation. * (see sparse.c::memory_present()) * * Making it a UL at least makes someone do a cast * before using it wrong. */ unsignedlong section_mem_map;
Context switches and TLB flushes can change individual bits of CR4. CR4 reads take several cycles, so store a shadow copy of CR4 in a per-cpu variable. To avoid wasting a cache line, I added the CR4 shadow to cpu_tlbstate, which is already touched during context switches.
typedefstructpglist_data { structzonenode_zones[MAX_NR_ZONES]; structzonelistnode_zonelists[MAX_ZONELISTS]; int nr_zones; #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */ structpage *node_mem_map; #ifdef CONFIG_PAGE_EXTENSION structpage_ext *node_page_ext; #endif #endif #ifndef CONFIG_NO_BOOTMEM structbootmem_data *bdata; #endif #ifdef CONFIG_MEMORY_HOTPLUG spinlock_t node_size_lock; #endif unsignedlong node_start_pfn; unsignedlong node_present_pages; /* total number of physical pages */ unsignedlong node_spanned_pages; /* total size of physical page range, including holes */ int node_id; wait_queue_head_t kswapd_wait; wait_queue_head_t pfmemalloc_wait; structtask_struct *kswapd;/* Protected by mem_hotplug_begin/end() */ int kswapd_order; enum zone_type kswapd_classzone_idx; int kswapd_failures; /* Number of 'reclaimed == 0' runs */ #ifdef CONFIG_COMPACTION int kcompactd_max_order; enum zone_type kcompactd_classzone_idx; wait_queue_head_t kcompactd_wait; structtask_struct *kcompactd; #endif #ifdef CONFIG_NUMA_BALANCING /* Lock serializing the migrate rate limiting window */ spinlock_t numabalancing_migrate_lock; /* Rate limiting time interval */ unsignedlong numabalancing_migrate_next_window; /* Number of pages migrated during the rate limiting time interval */ unsignedlong numabalancing_migrate_nr_pages; #endif unsignedlong totalreserve_pages; #ifdef CONFIG_NUMA /* * zone reclaim becomes active if more unmapped pages exist. */ unsignedlong min_unmapped_pages; unsignedlong min_slab_pages; #endif/* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */ ZONE_PADDING(_pad1_) spinlock_t lru_lock;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * If memory initialisation on large machines is deferred then this * is the first PFN that needs to be initialised. */ unsignedlong first_deferred_pfn; /* Number of non-deferred pages */ unsignedlong static_init_pgcnt; #endif/* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
structpage { /* First double word block */ unsignedlong flags; union { structaddress_space *mapping; void *s_mem; /* slab first object */ atomic_t compound_mapcount; /* first tail page */ };
/* Second double word */ union { pgoff_t index; /* Our offset within mapping. */ void *freelist; /* slub first free object */ };
union { #if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \ defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE) /* Used for cmpxchg_double in slub */ unsignedlong counters; #else unsigned counters; #endif struct { union { atomic_t _mapcount; unsignedint active; /* SLAB */ struct {/* SLUB */ unsigned inuse:16; unsigned objects:15; unsigned frozen:1; }; int units; /* SLOB */ }; atomic_t _refcount; }; };
/* Third double word block */ union { structlist_headlru; structdev_pagemap *pgmap; struct {/* slub per cpu partial pages */ structpage *next;/* Next partial slab */ #ifdef CONFIG_64BIT int pages; /* Nr of partial slabs left */ int pobjects; /* Approximate # of objects */ #else short int pages; short int pobjects; #endif };
structrcu_headrcu_head; struct { unsignedlong compound_head; #ifdef CONFIG_64BIT unsignedint compound_dtor; unsignedint compound_order; #else unsigned short int compound_dtor; unsigned short int compound_order; #endif };
movw%ss, %dx cmpw%ax, %dx# %ds == %ss? movw%sp, %dx je2f# -> assume %sp is reasonably set
# Invalid %ss, make up a new stack movw$_end, %dx testb$CAN_USE_HEAP, loadflags jz1f movwheap_end_ptr, %dx 1:addw$STACK_SIZE, %dx jnc2f xorw%dx, %dx# Prevent wraparound
2:# Now %dx should point to the end of our stack space andw$~3, %dx# dwordalign (might as well...) jnz3f movw$0xfffc, %dx# Make sure we're not zero 3:movw%ax, %ss movzwl%dx, %esp# Clear upper half of %esp sti# Now we should have a working stack # We will have entered with %cs = %ds+0x20, normalize %cs so it is on par with the other segments. pushw%ds pushw$6f lretw 6: # Check signature at end of setup cmpl$0x5a5aaa55, setup_sig jnesetup_bad # Zero the bss movw$__bss_start, %di movw$_end+3, %cx xorl%eax, %eax subw%di, %cx shrw$2, %cx rep; stosl # Jump to C code (should not return) calllmain
When executing a far return, the processor pops the return instruction pointer from the top of the stack into the EIP register, then pops the segment selector from the top of the stack into the CS register. The processor then begins program execution in the new code segment at the new instruction pointer.
SYM_FUNC_START_LOCAL_NOALIGN(.Lin_pm32) # Set up data segments for flat 32-bit mode movl%ecx, %ds movl%ecx, %es movl%ecx, %fs movl%ecx, %gs movl%ecx, %ss # The 32-bit code setsup its own stack, but this way we do have # a valid stack if some debugging hack wants to use it. addl%ebx, %esp
# Set up TR to make Intel VT happy ltr%di
# Clear registers to allow for future extensions to the # 32-bit boot protocol xorl%ecx, %ecx xorl%edx, %edx xorl%ebx, %ebx xorl%ebp, %ebp xorl%edi, %edi
# Set up LDTR to make Intel VT happy lldt%cx
jmpl*%eax# Jump to the 32-bit entrypoint SYM_FUNC_END(.Lin_pm32)
/* Set up %gs. * * The base of %gs always points to fixed_percpu_data. If the * stack protector canary is enabled, it is located at %gs:40. * Note that, on SMP, the boot cpu uses init data section until * the per cpu areas are set up. */ movl$MSR_GS_BASE,%ecx movlinitial_gs(%rip),%eax movlinitial_gs+4(%rip),%edx wrmsr .................. pushq$.Lafter_lret# put return address on stack for unwinder xorl%ebp, %ebp# clear frame pointer movqinitial_code(%rip), %rax pushq$__KERNEL_CS# set correct cs pushq%rax# target address in negative space lretq